Sisällöntunnistus 11,3 miljoonaan ajoneuvorekisterikorttiin – tekoälyllä jopa 60 % tehostus tietopalveluun

Segmentointi ja tekstintunnistus: näin tekoälyä hyödynnettiin uuden hakusovelluksen kehittämisessä.
Kansallisarkistossa olemme viime vuosina satsanneet tekoälyn käyttöön. Esimerkiksi reiluun kolmeen miljoonaan tekstitunnistettuun tuomiokirjasivuun voi tehdä sisältöhakuja Tuomiokirjahaku-verkkopalvelussa.
Nyt paransimme sisällöntunnistuksen avulla 11,3 miljoonan ajoneuvorekisterikortin käytettävyyttä tietopalvelussamme. Uuden hakusovelluksen myötä tietopyyntöihin vastaaminen on tehostunut jopa 60 prosenttia.
Kerromme seuraavaksi tarkemmin itse aineistosta sekä tekoälyn hyödyntämisestä uuden hakusovelluksen kehittämisessä.
Vuosittain noin 1 800 tietopyyntöä
Ajoneuvohallintokeskuksen arkistoon kohdistuu vuosittain jopa noin 1 800 tietopyyntöä. Kortteja tilataan esimerkiksi ajoneuvojen uudelleenrekisteröimistä sekä museokatsastuksia varten. Kortista selviää, milloin ajoneuvo on poistettu rekisteristä.
Vuosien 1965–1995 rekisterikortit on mikrofilmattu ja mikrofilmikopiot puolestaan digitoitu, minkä ansiosta tietopalvelua on pystytty tähänkin asti tekemään toimipaikasta riippumatta.
Työ on silti ollut hidasta. Rekisterikorttien etsimiseen on ollut käytössä useita tietokantoja, ja oikean poistotiedon löytämisen jälkeen rekisterikortti on vielä täytynyt haravoida esille Kansallisarkiston Astia-verkkopalvelusta.
Sisällöntunnistuksen tavoitteena oli yksinkertaistaa ja nopeuttaa tätä prosessia. Halusimme tuoda mahdollisimman paljon tietoa saataville yhdellä haulla.

Näin sisällöntunnistus toteutettiin
Koska ajoneuvohallintokeskuksen arkistoon sisältyvät rekisterikortit oli digitoitu jo aiemmin, niiden sisällöntunnistusta voitiin ryhtyä suunnittelemaan suoraan.
Digitoitua aineistoa oli jopa 11,3 miljoonaa kuvaa. Yksi kuva sisältää yhden tai useamman ajoneuvon rekisteritiedot, joten aineistoon sisältyy melkoisesti Suomessa rekisteröityjen ajoneuvojen historiaa.
Ajoneuvorekisterin sisällöntunnistus koostui kahdesta osa-alueesta: segmentoinnista ja tekstintunnistuksesta.
Segmentoinnissa tunnistimme ja merkitsimme rekisterikorteista ajoneuvojen rekisteri- ja valmistenumerot, joiden perusteella tietoa haetaan. Merkitsemistyöhön käytettiin sisällöntunnistuksen opetusaineistojen tekoa varten kehitettyä Label Studio -työkalua.
Ajoneuvorekisterikorttien ulkoasu vaihtelee paljon, joten opetusaineistoa oli oltava kattavasti kaikilta eri vuosikymmeniltä. Opetusaineistoa tehtiin yhteensä noin 800 dokumenttia.
Segmentoitujen aineistojen pohjalta koulutimme koneoppimismallin, joka tunnistaa rekisteri- ja valmistenumeroiden sijainnin kuvissa. Sen lisäksi rekisterikorttien prosessoinnissa käytettiin valmiiksi koulutettua tekstintunnistusmallia, jolle segmentoinnissa rajatut tekstialueet syötettiin.
Näitä kahta mallia käyttämällä kuvista pystyttiin poimimaan tietopalvelussa tarvittavat tiedot.
Sisällöntunnistuksen haasteita
Ajoneuvorekisterikorttien sisällöntunnistuksen työaikaa vievin vaihe oli 11,3 miljoonan kuvan siirtäminen prosessoitavaksi. Kansallisarkiston omalla laitteistolla toteutettu prosessointi puolestaan kesti yhteensä noin 30 vuorokauden verran.
Haasteita liittyy myös itse sisällöntunnistukseen, sillä sen tulos ei ole koskaan sataprosenttinen ja tunnistustulokseen jää väistämättä virheitä. Tekstintunnistusmalli on saattanut esimerkiksi tunnistaa nollan kirjaimena O. Tunnistusalueen rajaaminen on myös saattanut epäonnistua niin, että rekisteritunnuksen V-kirjaimesta tuleekin /-vinoviiva.
Isossa roolissa tunnistustuloksen onnistumisessa on sisällöntunnistettavan aineiston laatu. Jos digitaalinen kuva on liian huonolaatuinen, esimerkiksi sumea tai kuvausvaiheessa heilahtanut, ei siitä ole mahdollista saada sisällöntunnistettua dataa.
Ajoneuvorekisterikorttien kohdalla virheet otettiin huomioon lisäämällä hakusovellukseen mahdollisuus käyttää sumeaa hakua.
Sisällöntunnistuksen jälkeen 11,3 miljoonaa prosessoitua rekisterikorttien kuvaa tuli saada tietopalvelua tekevien käyttöön. Sitä varten ohjelmoimme mahdollisimman helppokäyttöisen hakusovelluksen.
Hakusovellus on tarkoitettu vain Kansallisarkiston sisäiseen käyttöön ja väliaikaiseksi työvälineeksi, sillä ajoneuvojen rekisterikortit tulevat lopulta haettavaksi Astia-palvelun kautta.
Sovelluksessa ajoneuvot ovat haettavissa rekisteri- ja valmistenumeroilla. Hakutuloksena saadaan kaikki ne rekisterikortit, joissa haettu numero esiintyy, sekä suora linkki aineistoon Astia-palvelussa.
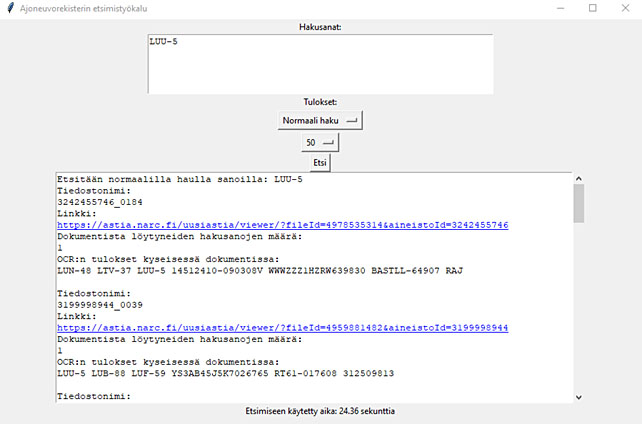
Tietopalvelu on tehostunut jopa 60 prosenttia
Aineiston prosessoinnilla ja hakusovelluksen rakentamisella tavoiteltiin tietopyyntötyötä tekevien ajan säästämistä ja palvelun tehostamista.
Tässä onkin jo onnistuttu, sillä aikaa on säästynyt noin 40–60 prosenttia verrattuna aiempiin toimintatapoihin – tietopyynnön tyypin mukaan. Etenkin aikaa vievien ajoneuvon omistushistorioiden selvittämisessä sisällöntunnistus ja uusi hakusovellus ovat auttaneet säästämään selvää aikaa.
Tulokset ensimmäisestä tietopyyntöpalvelun tehostamiseen tähtäävästä sisällöntunnistusteknologioiden käytöstä ovat myönteisiä. Työtä tullaan jatkamaan Kansallisarkistossa uusilla aineistoilla.
Pidempi versio tekstistä julkaistu alun perin Faili-lehden numerossa 4/23.
Lue lisää
- Arkistojen portin artikkeli ajoneuvojen rekisteröintiin liittyvistä asiakirjoista
- Tuomiokirjahaku-verkkopalvelu: tee sisältöhakuja yli 3 miljoonaan tekstitunnistettuun tuomiokirjasivuun 1800-luvulta.
Lisätietoja
- Ilkka Jokipii, yksikönpäällikkö, Tutkimus ja innovaatiot, [email protected]
- Sanna Joska, tutkija, Tutkimus ja innovaatiot, [email protected]