Älykkäitä hakuja, jalostettua dataa & sisällöntunnistusta – näin tekoälyä sovelletaan Euroopan arkistoissa

Miten hyvin Kansallisarkisto on tekoälykehityksen vauhdissa mukana? Matkaraportti Luxemburgin Tekoäly ja arkistot -työpajasta.
Kansallisarkiston Tutkimus ja innovaatiot -toiminto matkasi Luxemburgiin ottamaan selvää, kuinka tekoälyä hyödynnetään Euroopan arkistoissa.
Konrad Adenauer -rakennuksessa 16.11. järjestetty Tekoäly ja arkistot -työpaja oli tiimillemme oiva tilaisuus tarkastella toimintaamme suhteessa muihin sekä saada kehitysideoita tulevaan, kirjoittaa tutkija Lauri Leinonen.
Talon omasta tekoälykehityksestä riittäisi kerrottavaa muillekin:
- DALAI-hankkeessa olemme kehittäneet sisällöntunnistuskomponentteja ja nimettyjen entiteettien poimintaa ja
- HTR-projekteissa kehittäneet käsialamalleja sekä
- prosessointiputkia.
Tällä kertaa menimme paikalle kuitenkin vain kuuntelemaan ja keskustelemaan.
Itse tilaisuus käynnistyi Euroopan parlamentin pääsihteeristön alaisena toimivan Innovoinnin ja keskusyksiköiden osaston johtajan Susanne Altenbergin puheenvuorolla. Hän keskittyi tekoälyn viimeaikaiseen kehitykseen kuten suurten kielimallien läpimurtoon
Varsinaiseen asiaan päästiin esitelmien myötä. Nostamme yksityiskohtaisempaan tarkasteluun kolme erityisen kiinnostavaa esimerkkiä tekoälyn hyödyntämisestä arkistoissa.
Älykkäitä hakuja parlamentin arkistoaineistoon
Euroopan parlamentin arkiston Marco Amabilino esitteli alustaa, johon on viety parlamentin arkistoaineisto. Amazonin QuickSight-teknologialla tuotettu ratkaisu mahdollistaa aineistoon kohdistuvat älykkäät haut ja suodatukset sekä aineiston automaattisen tilastoinnin.
Content analysis -työkalu antaa ensi alkuun automaattisesti tuotetut sanapilvet rajatusta aineistosta.
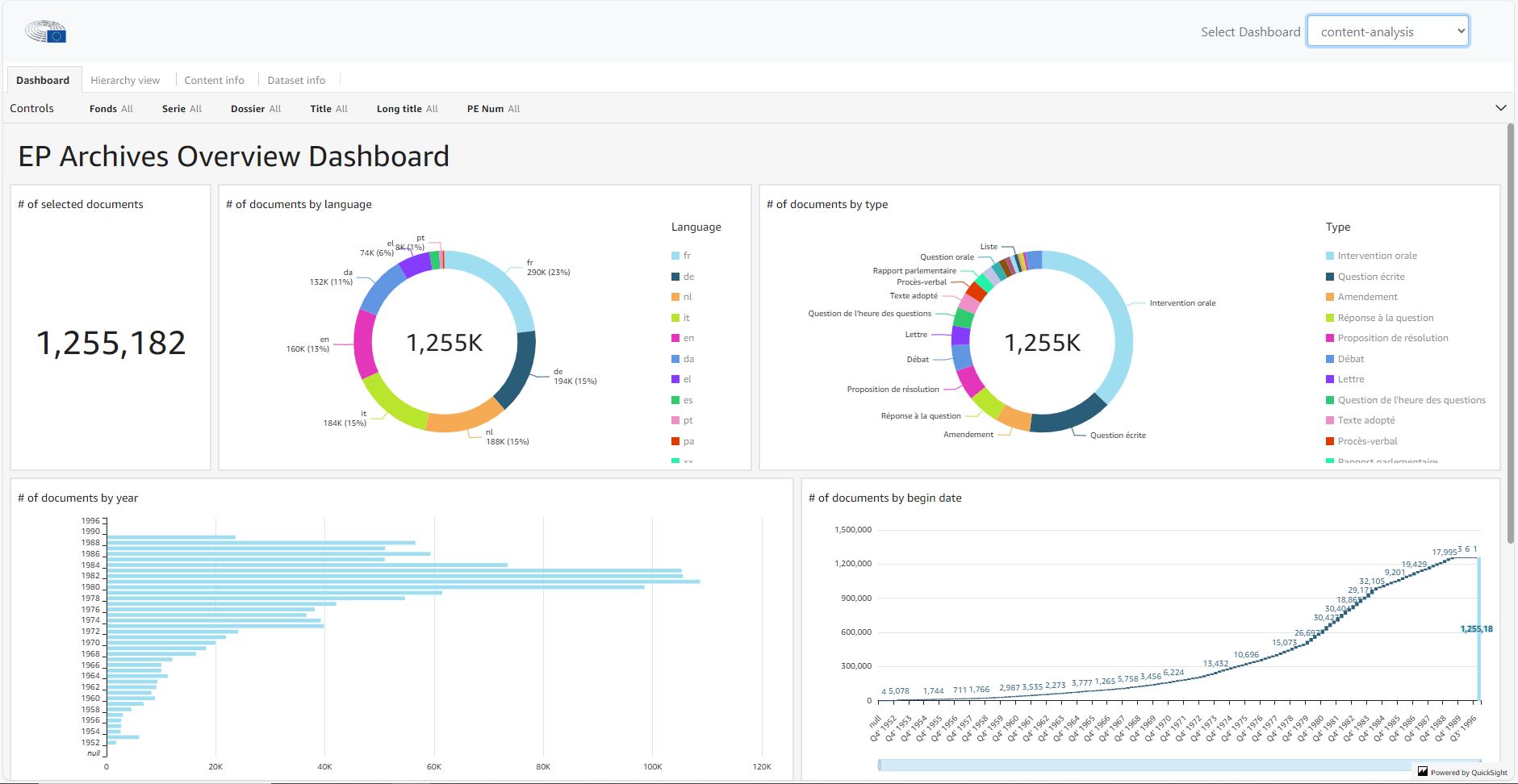
Advanced content search -välilehdellä voi etsiä suoraan tekstitunnistetusta sisällöstä vapain hakutermein. Samaan hakukenttään voi esittää kielimallia hyödyntävälle älykkäälle hakukoneelle kysymyksiä. Esimerkiksi hakemalla ”Robert Schuman” saa häneen liittyvät asiakirjat, kun taas kysymällä ”Quand est né Robert Schuman?” hakee palvelu suoraan vastauksen kysymykseen.
Samasta näkymästä kannattaa huomioida myös vasemman reunan asiasanaryhmittelytyökalut, jotka järjestelmä generoi dynaamisesti suoraan aineistosta – kyseessä ei siis ole ihmiskäsin syötetty metatieto.
Kokonaisuus on erittäin toimiva, ja sen avulla voi löytää ja käsitellä aineistoja useilla eri tavoilla. Palvelulla on tietenkin hintansa, mutta vastaavia mahdollisuuksia löytyy myös avoimen lähdekoodin puolelta.
Aineistojen yhdistelyä datan jalostamisella
Toinen mainitsemisen arvoinen kokonaisuus olivat Luxemburgin yliopiston tuottamat palvelut ja kokeilut aineiston kanssa. Näistä valmiina työkaluna on mainittava Impresso-alusta.
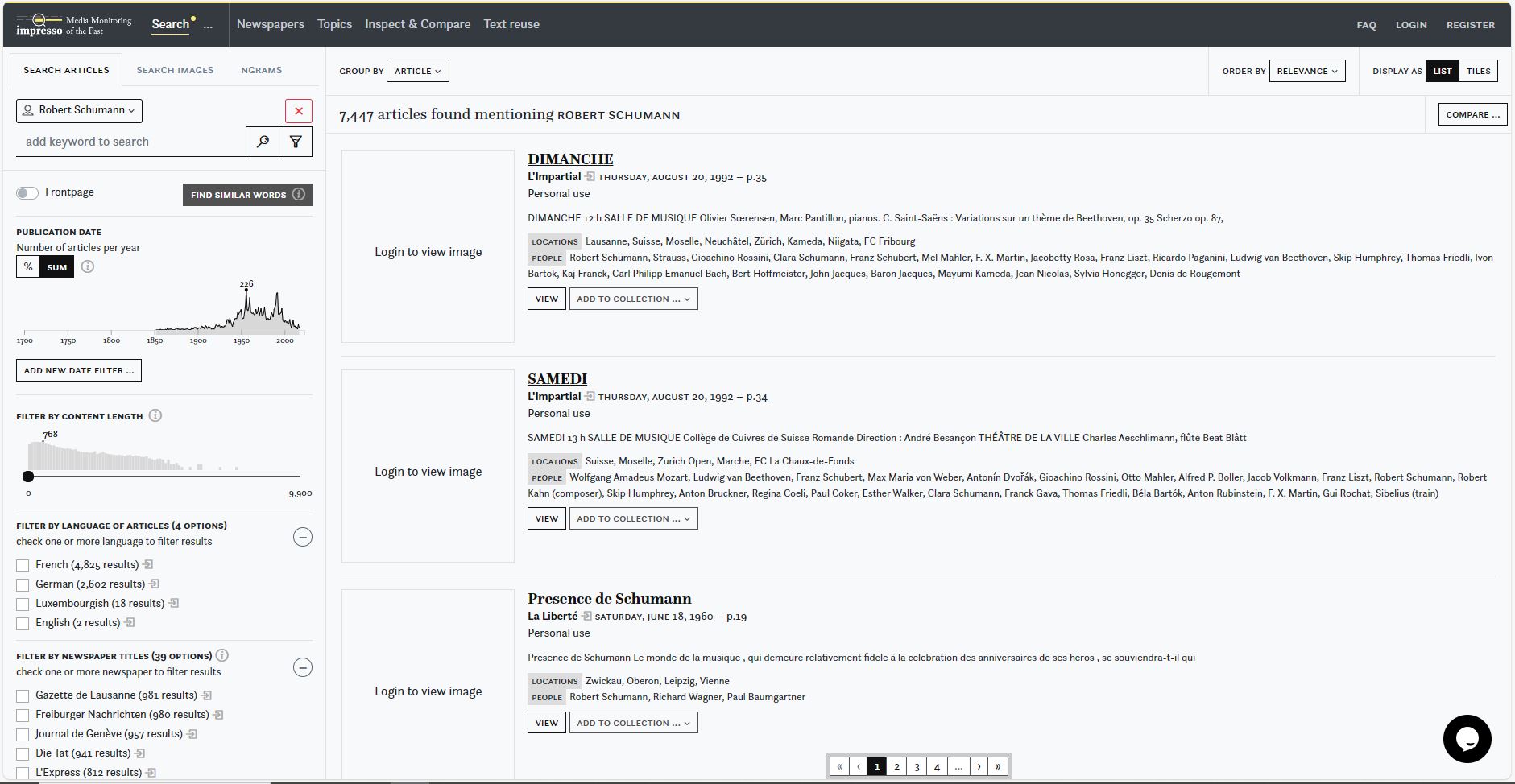
Impresso yhdistää sanomalehtiaineistoa radio-ohjelmiin ja tarjoaa paljon työkaluja tekstitunnistetun sisällön analysointiin. Näihin työkaluihin kuuluu mm. aihemallinnus, nimettyjen entiteettien tunnistus sekä tekstilainojen tunnistustyökalu.
Datan jalostamisella on saatu yhdistettyä suhteellisen luotettavasti aineisto, joka lähtötilanteessa sisälsi paljon epätarkkuutta ja kohinaa sekä puutteellisia metatietoja – tai vähintään on kyetty luomaan käyttäjälle työkalut, jotka mahdollistavat aineiston yhdistämisen tutkimuksen kannalta kiinnostavien kokonaisuuksien löytämiseksi.
Datapuolen työkalujen lisäksi alusta on esimerkillinen käyttöliittymäsuunnittelultaan ja käyttäjän opastukseltaan. Kohdeyleisönä palvelulla on tutkijakäyttäjä, mikä näkyy tehdyissä valinnoissa.
Luxemburgin yliopiston toisessa esitelmässä näytettiin peräti kolme eri työkalua tai hanketta, joilla aineistoa jalostettiin. Ensimmäinen hanke rakensi liukuhihnaa tekstiaineiston (tässä tapauksessa historiallisten maahanmuuttoasiakirjojen) muuntamiselle digitaaliseen muotoon keskeiset datat poimien ja jatkojalostaen.
Muissa kahdessa hankkeessa keskityttiin kuvanlaadun parantamiseen tekoälyavusteisesti sekä suurten kielimallien hyödyntämiseen arkistoaineiston jatkojalostamisessa, muun muassa metatietojen tuottamisessa sekä aineiston löydettävyyden parantamisessa.
Kokonaisuutena hankkeet tulevat hyvin lähelle Kansallisarkistollakin tehtyjä ja suunniteltuja projekteja. Vastaavia työkaluja on meillä kehitetty muun muassa tutkimustietokantojen puitteissa, kantakorttien sisältötunnistukseen sekä aineiston metadatan tuotantoon ja asiasanoittamiseen.
Sisältötunnistus sotavankikortistoon
Kolmantena ja viimeisenä on nostettava esiin Unkarin kansallisarkiston tekemä työ. Unkarissa on tuotettu mm. neuvostoajan sisältötunnistettuihin sotavankikortistoihin kohdistuva verkkopalvelu, jonka kautta yksittäisten henkilöiden vankitaival on selvitettävissä.
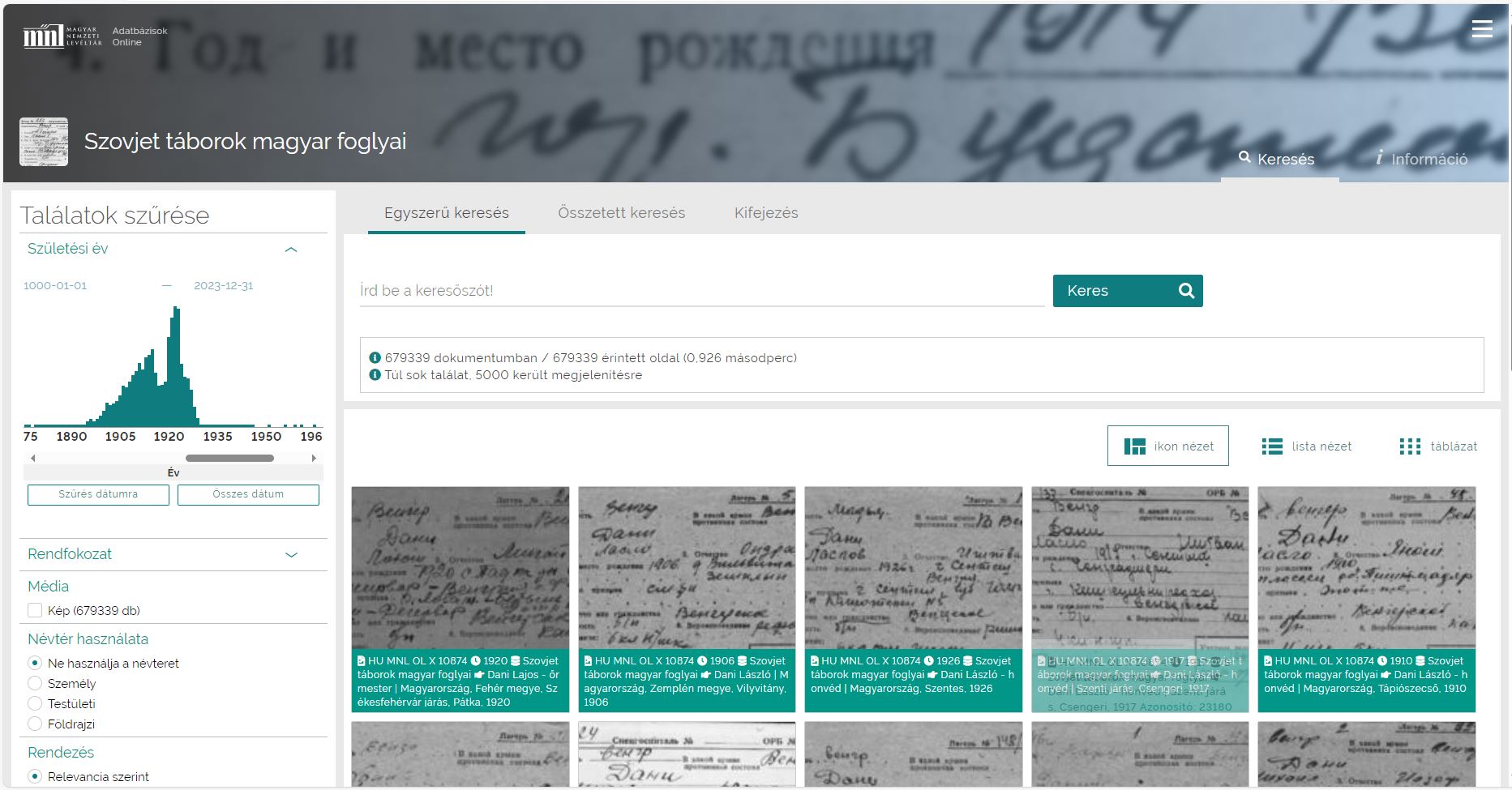
Sovellutuksen teossa on käytetty tekoälykomponentteja muun muassa tunnistamaan ja yhdistämään eri kielillä esiintyvät nimientiteetit aineistoista.
Unkari on vastaavasti kuin mekin kehittämässä omia ratkaisujaan tekstintunnistukseen ja irtaantumassa Transkribuksesta alustana.
Sovellutuksia oli esittelemässä Zoltán Szatucsek, jonka kanssa sovimme kehitettyjen työkalujen jaosta arkistojemme välillä.
Epäonnistu nopeasti
Yleisenä teemana esitelmästä toiseen toistui nykytermein ”ketteryys”. Kehitys tekoälyrintamalla on äärimmäisen nopeaa. Mikäli organisaatio haluaa säilyttää itsenäisyytensä toimijana, on sen seurattava kehitystä aktiivisesti ja oltava avoin. Tämä vaatii nopeaa reagointia, suurta joustavuutta ja kokeiluhenkeä koko organisaatiolta.
”Fail fast” periaatteena toistui esitelmästä toiseen: on parempi kokeilla nopealla syklillä, mikä toimii ja mikä ei, kuin jäädä kiinni liiallisiin määrittelyihin ja täydellisyyden etsimiseen. Samoin on tunnistettava ne kohteet, joissa oma kehitys ei kannata suhteessa valmiiden palveluiden ostoon.
Tämän suhteen on kuitenkin tunnustettava täysin uuden teknologian hankinnan monimutkaisuus sekä sen vaatimukset organisaatiolle itselleen – aihe, josta Euroopan unionin Historiallisen arkiston Samir Musa piti erittäin kuvaavan esitelmän.
Musa esitteli organisaationsa läpikäymän tekoälyratkaisun hankintaprosessin. Alkuvaiheessa mahdollisia toteuttajatahoja tunnistettiin noin 300. Näistä kymmenesosaankin karsitun joukon toteutusratkaisut työmääräarvioineen ja teknologioineen erosivat toisistaan äärimmäisen paljon. Ostajan vastuulla oli tunnistaa tarjottujen ratkaisujen hyödyt ja arvottaa ne.
Osaltaan tämä hajanaisuus ja hankinnan vaatimukset ovat seurausta arkistoaineistojen monimutkaisuudesta, osaltaan nousevien teknologioiden varianssista. Samalla on selvää, että osaamista tekoälyratkaisuista on organisaatioissa hankittava ja ylläpidettävä, jotta hankintoja on ylipäätään mahdollista toteuttaa tuloksellisesti.
Esitelmissä käytettyjä teemoja veti yhteen loppupuheenvuorossaan Euroopan parlamentin arkistoyksikön johtaja Ludovic Delépine. Hän tiivisti päivän annin neljään teesiin, jotka liittyvät ennen kaikkea rohkeiden kokeilujen tarpeeseen ja organisaatiokulttuuriin: Think Big – Start small – Learn swiftly – Scale fast. (Ajattele isosti – aloita pienestä – opi sukkelasti – skaalaa nopeasti).

Kansallisarkisto hyvin vauhdissa mukana
Kokonaisuutena päivä oli Kansallisarkiston näkökulmasta antoisa. Saimme vahvistusta sille, että teemme oikeita asioita, ja että olemme tekemisessämme yleiseurooppalaisessa vauhdissa hyvin mukana. Kansallisarkistolla tällä hetkellä toteutettavat tekoälytyökalut ovat teknologisesti ajantasaisia, ja prosessoimamme aineiston määrä on Euroopan parhaimmistoa.
Samalla tuli selväksi, että omaa toimintaamme on suoraviivaistettava. Tekemiseemme on tuotava sekä osaamista ja järjestelmällisyyttä että joustavuutta ja ketteryyttä uudella tavalla, jotta organisaationa olemme valmiita kohtaamaan huomisen haasteet ja pysymään vauhdissa mukana.
Kehitteillä tällä hetkellä olevat hankkeet kuten taulukkomuotoisen aineiston sisällöntunnistus, kehittyneemmät käsialantunnistusmallit ja tekoälykomponenteista koostuvat prosessointiputket koskettavat jokaista talomme työntekijää ja asiakasta sekä muuttavat aineistojemme käyttötapoja.
Meidän on oltava valmiita tarkastelemaan omia työtapojamme, ja suoraviivaistamaan yhteistyötä aineiston digitoinnin, metadatan tuotannon ja sovelluskehityksen kesken, jotta kykenemme kokeilemaan ja skaalaamaan erilaisia ratkaisuja nopeasti ja tarjoamaan niitä asiakkaille ripeästi.
Arkistojen kannalta käsillä on tekoälyn tuoma murros aineiston käsittelytavoissa. Kansallisarkisto on valmis vastaamaan haasteeseen.
Kirjoittaja: Lauri Leinonen
Lisätietoja
- Ilkka Jokipii, yksikönpäällikkö, Tutkimus ja innovaatiot, [email protected]
- Lauri Leinonen, tutkija, Tutkimus ja innovaatiot, [email protected]